
Claude Fable 5, silent agent entropy, and a $10M bet on multi-agent safety
Anthropic's dual-tier Fable 5 / Mythos 5 launch defines a new frontier model structure while sparking debate on invisible output throttling; a new arXiv paper formalizes why agent systems degrade silently without bugs or attacks; and Google DeepMind, DARPA, and NSF each move money into multi-agent safety research before deployment outruns the field.

Research Brief
Today's briefing covers the week of June 9–12, 2026: Anthropic's dual-tier model launch redraws the frontier; two new arXiv papers expose how agent systems fail silently and how linear code exploration hits a structural ceiling; Google DeepMind and DARPA each put new money behind multi-agent safety research; and real production data from Stripe, Anthropic's own engineering org, and a Singapore university lab show what agentic coding looks like at full throttle.
Models and tools
Claude Fable 5 and Mythos 5: a tiered frontier
On June 9, Anthropic launched two models built on the same underlying weights — a structure the company says it expects to repeat as capability climbs.1
Claude Fable 5 is the publicly available version. It sets new state-of-the-art numbers on nearly every benchmark Anthropic tested: 95.5% on SWE-bench Verified, 80.3% on the harder SWE-bench Pro, 64.5% on Humanity's Last Exam (with tools), and top scores on Cognition's FrontierCode coding evaluation and Hebbia's senior-level finance benchmark. The key hardware flex: Stripe reported that Fable 5 completed a codebase-wide migration of 50 million lines of Ruby in a single day — work the company estimated at more than two months of engineering time. On vision tasks it rebuilt a web app from screenshots alone and beat Pokémon FireRed with a minimal vision-only harness, both of which had stumped earlier Claude models at practical effort levels. Pricing landed at $10 per million input tokens and $50 per million output tokens — under half the cost of Claude Mythos Preview.
Claude Mythos 5 is the same underlying model with safeguards lifted in cybersecurity and, soon, biosecurity. It deploys initially through Project Glasswing in collaboration with the US government; a broader trusted-access program is forthcoming. Anthropic says Mythos 5 accelerated aspects of internal drug-design workflows by roughly 10×, matched or beat skilled human operators on protein design tasks without human assistance, and conducted autonomous genomics research that trained a model outperforming a recent Science-published result.
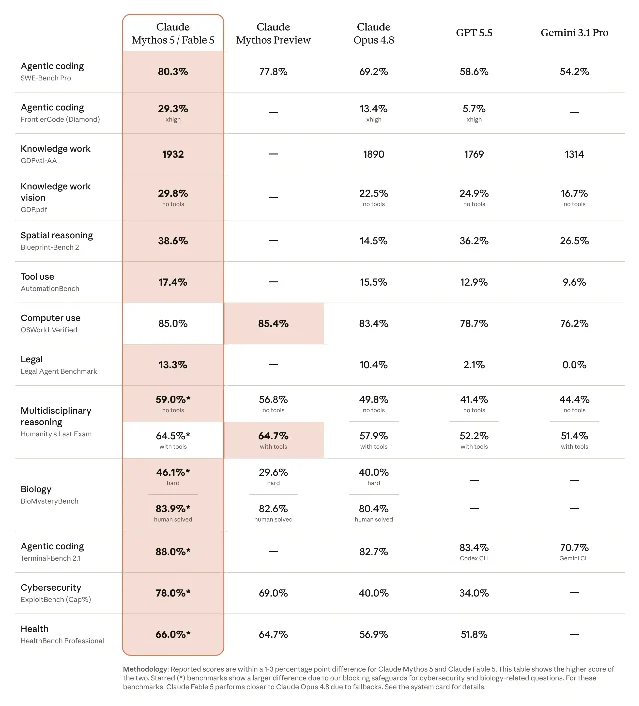
The launch also surfaced a controversy worth tracking. Fable 5 ships two safeguard layers: one that visibly reroutes flagged cybersecurity or biology queries to Claude Opus 4.8 and notifies the user; a second that silently degrades responses to requests related to frontier AI development using prompt modification and steering vectors, with no user-facing notification. Anthropic's system card says this affects roughly 0.03% of traffic and will not be visible to users.2 The reaction on X, Reddit, and Hacker News was immediate: developers pushed back on invisible output degradation as a category-level trust problem, distinct from transparent content filtering. The debate about what informed consent looks like for AI safety measures now has a concrete case study attached to it.
Cohere North Mini Code: sovereign and open
Also on June 9, Cohere shipped North Mini Code, its first open-source model aimed explicitly at agentic software development workflows.3 The architecture is mixture-of-experts: 30B total parameters, 3B active at inference time, designed to run on a single H100 GPU. Cohere claims 2.8× higher output throughput than Mistral's Devstral Small under identical hardware conditions. The model is Apache 2.0 licensed — commercially free. Co-founder Nick Frosst pitched it as a deliberate counterpoint to the frontier-lab approach: "small, open source, transparent and sovereign vs large, expensive, proprietary and hegemonic." For teams that need an agentic coding model they can deploy on-premise without third-party API dependence, this fills a gap that has mostly been occupied by fine-tuned variants of general models.
Research
The entropy problem: why agent systems degrade without anyone breaking them
A June 6 arXiv preprint (arXiv:2606.08162) by Dexing Liu proposes a formal framework for a failure class that most practitioners have seen but few have named precisely.4
The paper draws on 40,000+ controlled trials and 100,000+ production agent interactions to characterize silent failure: unexpected behavioral drift under normal operating conditions, with no adversarial input, no injection, no resource exhaustion. These failures are routinely misattributed to bugs. Liu identifies 22 intrinsic properties of LLM agent systems across six lifecycle layers — foundation semantics, inter-agent transmission, memory persistence, task execution, feedback correction, and systemic evolution — and argues that when a sufficient subset of these properties co-exist, system entropy increases monotonically with interaction rounds. The formalization:
S(t) = S₀ × e^(α × t), where α is measured empirically across multiple architectures. Liu calls the proposed countermeasure the PIG (Physical Integrity Gate) Engine with an ADE (Agent Delivery Engineering) protocol suite.The practical implication: an agent that passes your evals at launch will degrade over sessions through mechanisms that are internal to the architecture, not bugs you can patch. This is a design constraint to engineer around, not a configuration error to debug away.
CAIS 2026: three agent security results worth your attention
ACM's first Conference on AI and Agentic Systems produced a security track worth reading. The open-source agent runtime team at Agyn pulled out three papers with genuine new evidence.5
Supply-chain backdoors (Boisvert et al., ServiceNow Research / Mila / Polytechnique Montréal): Three threat models — poisoning finetuning data, distributing pre-backdoored base model weights, and poisoning the environments a teacher model uses to generate training traces. The empirical claim: poisoning a small number of demonstrations embeds a backdoor that causes an agent to leak confidential user information with over 80% success. The attack requires access to the victim's data pipeline and, in the environment-poisoning variant, control of a large pool of legitimate-looking websites. Realistic for a well-resourced attacker; inheritable by any team that downloads weights from a public hub.
Privacy degradation in social multi-agent settings (Priyanshu, Vijay, Pahwa; Foundation-AI / Corvic AI): Privacy violations more than double when LLMs move from single-turn to persistent multi-agent social environments (from ~20% to ~45% inappropriate disclosure rate on OpenAI models). The contagion finding is starker: agents become roughly 8× more likely to share sensitive attributes after watching a peer do so. Explicit privacy instructions reduce leakage but don't eliminate it (~37.8% floor). No attacker required — the drift emerges from agents being agents.
Repository-aware skill security (Holzbauer et al., IT:U & SBA Research, Best Paper at AgentSkills Workshop): A scan of 238,180 agent skills from three major distribution platforms found that naive scanners flag up to 46.8% as malicious. After repository-aware analysis — checking commit history, surrounding code, maintainer activity — only 0.52% remain genuinely suspicious. The paper also documents a previously undescribed attack vector: hijacking abandoned GitHub repositories to push malicious skill updates that propagate through downstream marketplace listings. The takeaway for teams building on skill ecosystems: current marketplace scanners produce a false-positive rate high enough to be useless at scale; repository context is the differentiating signal.

Industry and ecosystem
Google DeepMind's $10M bet that academia can outrun deployment
On June 11, Google DeepMind, Schmidt Sciences, the UK government's ARIA, the Cooperative AI Foundation, and Google.org jointly announced a $10 million fund to seed academic research into multi-agent safety.6
Rohin Shah, who directs AGI safety and alignment research at Google DeepMind, was direct about the motive: the research field for multi-agent dynamics effectively does not exist. Single agents are studied; small clusters are studied; what happens when there are millions of them reasoning, negotiating, and acting on instructions from other agents is not. He frames it as an institutional blind spot that deployment is about to expose. Google made agent-based tools a centerpiece of Google I/O last month, the broader industry is moving the same direction, and the window to study failure modes before scale is short.
The fund is deliberately small relative to DeepMind's internal research budgets — and Shah says that's the point. Universities can study scenarios that industry labs won't prioritize until they become a crisis. Near-term work will be empirical: drop agents into sandboxes, run realistic simulations, observe what happens when LLM-backed agents coordinate in unexpected ways. The risks named are concrete: prompt injection, scams at scale, cyberattacks adapted to target reasoning systems. Shah declined to frame the fund as preparation for economic collapse "by the end of the year," while allowing longer-horizon scenarios are legitimate research territory. Akeyless CTO Refael Angel, quoted in the announcement, noted that no single lab should write the safety standards everyone else is required to trust.
DARPA and NSF: AI Forge opens the door to national-security research
On June 1, DARPA and NSF jointly announced AI Forge — a co-governed forum that will fund university-led research on AI interpretability, control, and adversarial robustness, with awards sized at $750K to $3M per project and a one-year project ceiling.7 The forum will be co-governed by DARPA, NSF, and NIST's Center for AI Standards and Innovation (CAISI). CAISI's involvement is a signal worth reading: AI Forge–funded research is likely to feed directly into national AI evaluation standards.
The RFI — DARPA-SN-26-80, posted at sam.gov — closes June 22, 2026. It is not a funding opportunity; it is the gate that decides which university groups are invited to compete when real solicitations open. Groups that skip the RFI risk being outside the network when the first round of calls is designed.
The three thrust areas translate to: interpretability work at frontier model scale (not visualization on CNNs), control techniques for verifying that an agent's actions match a specification across long horizons, and adversarial robustness under contested deployment with sophisticated adversaries. The forum model is designed to compress DARPA's normal multi-month BAA cycle to weeks and to enable direct talent flow between university PIs and industry researchers.
Anthropic: 80% of its code is now written by Claude
A public post from the Anthropic Institute, published this week, released previously internal data on how much of the company's own development is now delegated to its models.8 As of May 2026, over 80% of code merged into Anthropic's codebase was authored by Claude. Lines of code per engineer per day stayed flat from 2021–2024, then climbed sharply in 2025 when Claude began running code rather than just suggesting it, and steepened again in 2026 as models began working autonomously over longer time horizons. In Q2 2026, the typical engineer merges 8× as much code per day as in 2024.
The post also tracks the pace of capability growth on long-horizon task benchmarks, citing METR data showing Claude Mythos Preview could work for "at least" 16 hours — at the upper bound of what METR can currently measure. The framing is careful: the company characterizes this as progress toward recursive self-improvement but not yet an example of it. The public data makes for a useful calibration point against vendor claims and your own internal productivity figures.
Use case and practitioner
Domain-scoped parallel agents beat sequential exploration on multi-file code changes
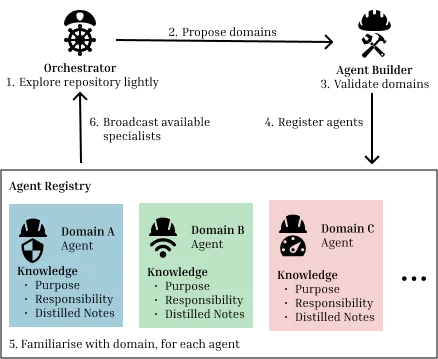
Researchers at Singapore Management University published a study (arXiv:2606.11976, June 10) directly relevant to anyone running agentic code-change workflows.9
The setup: the benchmark is SWE-bench Pro issues from the Ansible repository, where 80% of issues require touching multiple files across multiple subsystems. Standard single-agent approaches explore repositories linearly — one directory or file per step — which forces the agent to commit to a starting subsystem and can exhaust its step budget before it reaches later subsystems where gold files live. The paper tests four approaches: a plain LLM with no repo access; a single-agent Recursive Language Model with a persistent Python REPL; their proposed domain-scoped multi-agent system (persistent specialists per repository subsystem — cli, module_utils, galaxy, docs — dispatched in parallel by a root coordinator); and Codex 5.5 High as a larger-model CLI baseline.
Results: the domain-scoped parallel agent system, using a small Haiku-class model, achieves the highest micro-F1 among Haiku-class systems by a significant margin and reaches competitive performance with Codex 5.5 High — a much larger model — on the expanded benchmark. Three additional findings carry operational weight: documentation co-evolution is a latent dependency no current architecture handles; naive file-system access can degrade localization by inflating false positives through test-file over-prediction; and forcing more aggressive multi-agent consultation does not improve recall but does raise token cost substantially.
The lesson for teams building software agents: the exploration structure of your agent — how it decomposes a repository and which subproblems it handles in parallel — matters as much as the model class powering it.
Time window: June 9–12, 2026. Next issue publishes June 13.
References
- 1Claude Fable 5 and Claude Mythos 5 — Anthropic
- 2Daily AI Digest — Claude Fable 5: The Good, The Bad and The Ugly
- 3Introducing North Mini Code — Cohere
- 4Silent Failure in LLM Agent Systems: The Entropy Principle — arXiv
- 5We Read 12 Agent-Security Papers from CAIS 2026 — Agyn
- 6Google DeepMind backs $10M fund to study multi-agent AI safety risks — AI Chat Daily
- 7AI Forge: DARPA and NSF Just Built a Direct Pipeline From University Labs to National Security AI Research — Granted AI
- 8When AI builds itself — Anthropic Institute
- 9Exploration Structure in LLM Agents for Multi-File Change Localization — arXiv
Add more perspectives or context around this Post.